
Content-based Recommender System for Movies with Tensorflow
Low-level use of TensorFlow to recommend unseen movies to users.

Doctor in Computer Sciences. Researcher Professor.
Introduction
A content-based recommender is a type of system that makes recommendations to users based on their preferences and considers product attributes. This sounds very much like the Amazon "if you liked that, maybe you might also like this..." type of recommendation.
The idea is to recommend something the user has never rated before. When I say "rated" means it probably hasn't visited, rated, or clicked it before.
In a real setting, you can change rates for visited, clicked, or watched. You might also find some other metric to describe the interest of the user in a certain product.
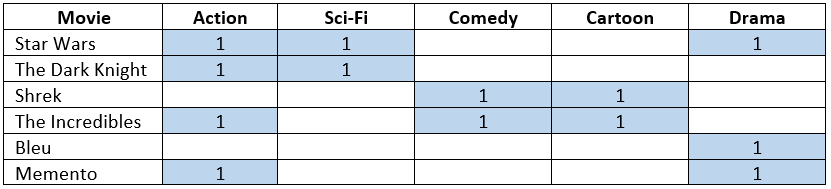
The example below is a hello-world type of example where we are going to recommend movies to users. We will only have 4 users and 5 movies:'Star Wars', 'The Dark Knight', 'Shrek', 'The Incredibles', 'Bleu', and 'Memento'. Each movie is described by its genre. however we will use one-hot encoding for the genres: 'Action', 'Sci-Fi', 'Comedy', 'Cartoon', 'Drama'.
Let's start coding. The first thing to do is to represent User ratings and Movie features as tensors (matrices).
Let's start by loading Tensorflow and Numpy.
import numpy as np
import tensorflow as tf
Load Data
We have the following data from 4 users that rated some movies. We also have the metadata from 6 movies described by the genre. Let's keep some arrays with the user names and movie names for later use.
users = ['Juan', 'Daniel', 'Ana', 'Christian']
movies = [
'Star Wars', 'The Dark Knight', 'Shrek',
'The Incredibles', 'Bleu', 'Memento'
]
features = ['Action', 'Sci-Fi', 'Comedy', 'Cartoon', 'Drama']
num_users = len(users)
num_movies = len(movies)
num_feats = len(features)
num_recommendations = 2
The following table shows the preferences shown by users for some of the movies. There are blank spaces as not all the users have watched all the movies.

The users_movies tensor contains the information from the table. Let's load this information manually.
users_movies = tf.constant([
[4, 6, 8, 0, 0, 0],
[0, 0, 10, 0, 8, 3],
[0, 6, 0, 0, 3, 7],
[10, 9, 0, 5, 0, 2]], dtype=tf.float32)
Let's do the same thing with the movies_feats. The following tensor will contain the genre metadata for each movie as seen in the table above.
movies_feats = tf.constant([
[1, 1, 0, 0, 1],
[1, 1, 0, 0, 0],
[0, 0, 1, 1, 0],
[1, 0, 1, 1, 0],
[0, 0, 0, 0, 1],
[1, 0, 0, 0, 1]], dtype=tf.float32)
User Embeddings
Now that we have those tensors with user and movie data, we need to create the user embeddings. The user embeddings show the relationship between each user and the movies by performing matrix multiplication. We can easily achieve this with the tf.matmul (yes, for matrix multiplication) in TensorFlow.
users_feats = tf.matmul(users_movies, movies_feats)
users_feats
This will print the following tensor:

As we can see, this is basically telling us how important is each feature for each user. We must normalize each row so that each value adds to 1. The following code normalizes each row:
users_feats = users_feats / tf.reduce_sum(users_feats, axis=1, keepdims=True)
users_feats

The user_feats tensor now has normalized values for each user (row) and for each feature (column).
Ranking Features for Each User
The user_feats tell us how important is each feature for each user. Let's print this so we can understand the preferences of each user by the calculated weights.
The top_users_features is a tensor that returns the sorted indices of the most important attributes for each row. We are basically sorting each row and returning the index for each attribute. We will later loop and print the name of each feature name.
We find the top-k values of each row with the "tf.nn.top_k" function form tensorflow.
top_users_features = tf.nn.top_k(users_feats, num_feats)[1]
top_users_features
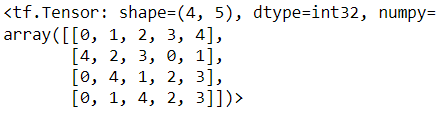
The tensor above shows the indices of the features that are more relevant for each user. The following code prints, for every user, the name of what seems to be more relevant to them:
for i in range(num_users):
feature_names = [features[int(index)] for index in top_users_features[i]]
print('{}: {}'.format(users[i], feature_names))
- Juan: ['Action', 'Sci-Fi', 'Comedy', 'Cartoon', 'Drama']
- Daniel: ['Drama', 'Comedy', 'Cartoon', 'Action', 'Sci-Fi']
- Ana: ['Action', 'Drama', 'Sci-Fi', 'Comedy', 'Cartoon']
- Christian: ['Action', 'Sci-Fi', 'Drama', 'Comedy', 'Cartoon']
So Juan and Christian prefer Action and Sci-Fi, and Daniel (and Ana) prefer Drama and Comedy. Please note that they all have different preferences and in different order as defined in the users_feats tensor.
Find Similarity Between Users and Movies
Now, we need to calculate the similarity between the user ratings and the movie features (already calculated in the users_feats tensor). The idea is to create the projected ratings for each movie and store them in a new tensor called users_ratings.
users_ratings = [tf.map_fn(lambda x: tf.tensordot(users_feats[i], x, axes = 1),
tf.cast(movies_feats, tf.float32))
for i in range(num_users)]
In this code, we are using dot-product as a similarity measure between the tensors to calculate the projected ratings. This tensor will now serve as the prediction for the entire dataset. The higher the dot-product, the more we will recommend the movie. The only problem with this is that we don't want to recommend movies the user has already seen, so we will remove the movie the user has already seen by applying a mask to the users_ratings tensor.
The first thing we will do is to create the tensor users_unseen_movies which will have a True if the movie has not been rated by the user and False otherwise.
users_unseen_movies = tf.equal(users_movies, tf.zeros_like(users_movies))
users_unseen_movies

The ignore_matrix is just a tensor the same size as the users_movies filled with zeros. This will serve as a base tensor to fill with only the probabilities of the unseen movies.
ignore_matrix = tf.zeros_like(tf.cast(users_movies, tf.float32))
ignore_matrix

Now, the magic is created with the tf.where function from tensorflow, which is able to apply the mask to the users_ratings so that only the unseen movies are kept in the tensor.
users_ratings_new = tf.where(
users_unseen_movies,
users_ratings,
ignore_matrix)
users_ratings_new


As you can observe, now only the unsee movie probabilities are shown. These will be our movie recommendations!
Recommendation: Top 2 movies (from the users_ratings_new tensor)
We can now calculate all of the users to 2 movies with the tf.nn.top_k function. The following code will return the top-k indices for each row of the users_ratings_new matrix. Remember that the users_ratings_new rows represent the users and the columns the movies. The following code obtains the tensor with the top movies for each user:
top_movies = tf.nn.top_k(users_ratings_new, num_recommendations)[1]
top_movies
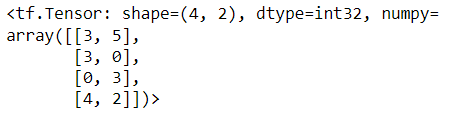
As we did previously, we can print the name of the user and the top-2 movies that are recommended for the user that it has never seen before!
for i in range(num_users):
movie_names = [movies[index] for index in top_movies[i]]
print('{}: {}'.format(users[i], movie_names))

Acknowledgments
This post has been a reproduction of the code provided by the Google Cloud Platform Data Analyst Recommender Systems program.




