
The Bias-Variance Trade-off Explained

Doctor in Computer Sciences. Researcher Professor.
What's Bias?
In machine learning, Bias refers to the difference between the predicted and expected values. Bias can also be defined as the error that is introduced by approximating a real-life problem. In supervised learning, we usually have a training and a validation set. The training set produces a model later used to predict the validation set. For example, a regression model that predicts the probability of getting into a pre-diabetic state based on glucose levels will learn the relationship between the levels and the labeled probability from the training set. The validation set contains real-life assessments of patients' glucose and their diagnosis as a probability. We say a model has low bias if the predicted probabilities are close to those in the validation set. Our objective while producing ML models is to reduce Bias as much as possible.
What's Variance?
Variance measures how much a prediction changes if we change the dataset. In other words, variance targets how strong our model is in making good predictions, given that we are using different datasets. Let's use the Glucose example. Suppose we collect data from San Jose, California, for our training set and train the model. Can the model predict successfully if we use a validation set from Albuquerque, New Mexico? The answer is probably not, and the reason is that both places have different diets that contain more or less sugar. We need to produce ML models that have low variance. This means that regardless of where we are testing the model (people from New Mexico, Ohio, New York, or California), the model should be able to withstand the changing assumptions (and dietary conditions) of the populations under evaluation.
How are They Related?
Bias and Variance are independent, but they affect the models simultaneously. A low-bias model produces good predictions. A high bias produces predictions that are far away from the expected values. A model with low variance is able to produce good predictions regardless of the incoming data, and a high variance model will cause inconsistencies in the results no matter where we test out the model. We always aim for low bias and low variance.
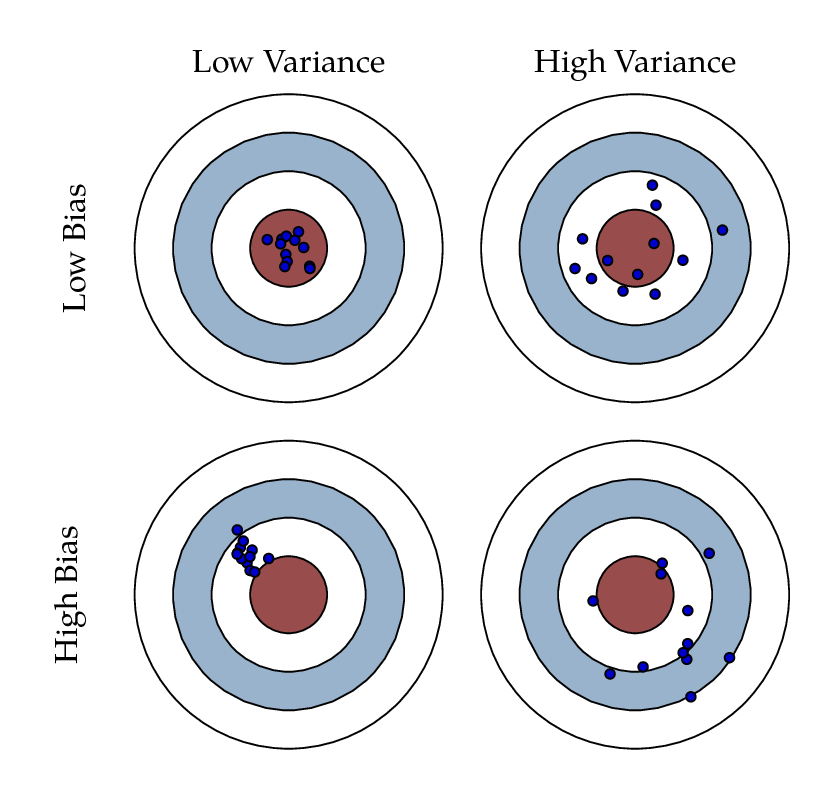
Why is this important in Machine Learning?
The bias-variance trade-off describes the balance we should consider when building machine learning models. Bias manages the model error (predictive), and the variance measures model sensitivity to changing data. This tells us something very important about this trade-off and how to deal with it: to manage Bias, we look at the model characteristics (features used and their quality, types of machine learning algorithms, hyperparameter tuning, etc.), and with Variance, we look for the quality of the data, sampling techniques, dimensional reduction, regularization, trustability of the data sources and data generalization. Let's look at each one separately.
What to do to reduce Bias?
Reducing model bias is crucial for improving the performance of a machine-learning model. Here are the main techniques to reduce model bias:
Increase Model Complexity:
Use more complex algorithms or models (e.g., switching from linear regression to polynomial regression or from a simple decision tree to a random forest).
Increase the number of features or use feature engineering to create more informative features.
Ensemble Methods:
Use ensemble techniques like bagging, boosting, or stacking to combine the predictions of multiple models, which can reduce bias.
Examples include Random Forests (bagging) and Gradient Boosting Machines (boosting).
Use Better Features:
Improve feature selection and engineering to include more relevant features that capture the underlying patterns in the data.
Use domain knowledge to create new features that might better explain the variance in the target variable.
Reduce Underfitting:
Ensure that the model is not too simple for the data. This might involve using more sophisticated algorithms or adding more parameters.
Avoid overly aggressive regularization, which can excessively penalize the complexity of the model, leading to high bias.
Data Augmentation:
- For problems like image recognition, data augmentation techniques (e.g., rotations, translations, flips) can create additional training examples, helping the model learn better.
Increase Training Data:
Collect more or better-quality data to provide the model with more information about the underlying patterns.
More data can help the model generalize better, reducing bias.
Hyperparameter Tuning:
Carefully tune hyperparameters to find the best settings that reduce bias without introducing too much variance.
Techniques like grid search, random search, or Bayesian optimization can be used for effective hyperparameter tuning.
Addressing Data Imbalance:
- For classification problems, ensure that the classes are balanced. Techniques like oversampling, undersampling, or synthetic data generation (e.g., SMOTE) can help.
Transfer Learning:
- Use pre-trained models (especially in deep learning) that have been trained on large datasets. Fine-tuning these models on your specific dataset can help reduce bias.
Regularization with Care:
- Use regularization techniques like L1 or L2 regularization judiciously. While they help in reducing variance, overly strong regularization can increase bias.
By applying these techniques, you can reduce model bias, helping the model to capture the underlying patterns in the data more accurately, which leads to better performance and generalization.
What to do to reduce Variance?
Reducing model variance is crucial for improving the generalizability of a machine-learning model. Here are the main techniques to reduce variance:
Simplify the Model:
Use simpler models with fewer parameters, such as linear regression, instead of polynomial regression or smaller decision trees.
This helps avoid overfitting by reducing the model’s capacity to fit the noise in the training data.
Regularization:
Regularization techniques like L1 (Lasso) or L2 (Ridge) regularization should be applied to penalize the complexity of the model.
Regularization discourages the model from fitting the noise in the training data, leading to a more generalizable model.
Ensemble Methods:
Ensemble techniques, such as bagging (e.g., Random Forests), can reduce variance by averaging the predictions of multiple models.
Boosting methods (e.g., Gradient-Boosting Machines) also help, but they primarily focus on reducing bias and can still improve generalization.
Cross-Validation:
Use cross-validation techniques to ensure that the model’s performance is consistent across different subsets of the data.
K-fold cross-validation helps understand how the model generalizes to unseen data and reduces the risk of overfitting.
Increase Training Data:
Collect more training data to provide the model with a better representation of the underlying distribution.
More data helps in reducing the model’s sensitivity to specific training examples.
Data Augmentation:
For tasks like image recognition, data augmentation techniques (e.g., rotations, translations, and flips) can artificially increase the size of the training dataset.
This helps the model to learn invariant features and reduces overfitting.
Pruning (for Decision Trees):
Apply pruning techniques to decision trees to remove unimportant branches that do not generalize well to new data.
Pruning helps simplify the model and reduce variance.
Early Stopping (for Neural Networks):
Use early stopping during training to halt the training process when performance on a validation set starts to degrade.
This prevents the model from overfitting to the training data.
Dropout (for Neural Networks):
Use dropout regularization in neural networks, where randomly selected neurons are ignored during training.
This prevents the network from becoming overly reliant on specific neurons and helps in reducing overfitting.
Bagging (Bootstrap Aggregating):
Train multiple models on different subsets of the data created through bootstrapping and aggregate their predictions.
This helps in reducing the model’s variance by averaging out the noise.
Parameter Tuning:
Carefully tune hyperparameters using grid, random, or Bayesian optimization techniques.
Proper hyperparameter tuning can help find the optimal balance between bias and variance.
By applying these techniques, you can reduce your model's variance, which leads to better generalization and improved performance on unseen data.
Where is overfitting in the trade-off?
Overfitting is a phenomenon in machine learning where a model learns the details and noise in the training data to such an extent that it negatively impacts the model’s performance on new data. In the context of the bias-variance trade-off, overfitting is primarily associated with high variance.
So, suppose the model has high variance, and the algorithm used in the training set is learning from all that noise. In that case, you will find that the accuracy will drop significantly when predicting the validation set.
Solutions to Overfitting
To mitigate overfitting and find a better balance in the bias-variance trade-off, the following techniques can be used:
Simplify the Model: Use a simpler model with fewer parameters.
Regularization: Add a regularization term to the loss function to penalize complex models (e.g., L1 or L2 regularization).
Cross-Validation: Use techniques like k-fold cross-validation to ensure the model’s performance is consistent across different subsets of the data.
More Training Data: Collect more training data to help the model learn the underlying patterns more effectively.
Pruning: For decision trees, apply pruning techniques to remove branches that do not provide additional power in predicting the target variable.
Dropout: In neural networks, use dropout to randomly ignore a subset of neurons during training to prevent the network from becoming too reliant on specific neurons.
Early Stopping: Halt the training process once the performance on a validation set starts to degrade.
Data Augmentation: For tasks like image recognition, use data augmentation to artificially increase the size and variability of the training dataset.
Summary
The variance-bias tradeoff is crucial because it helps build accurate and generalizable models, ensuring they perform well on unseen data. Balancing bias and variance is key to effective machine learning.



